EXPERIMENT 2
First Come First Serve (FCFS)
First Come First Serve CPU Scheduling Algorithm shortly known as FCFS is the first algorithm of CPU Process Scheduling Algorithm. In First Come First Serve Algorithm what we do is to allow the process to execute in linear manner.
This means that whichever process enters process enters the ready queue first is executed first. This shows that First Come First Serve Algorithm follows First In First Out (FIFO) principle
Example:
/*
* FCFS Scheduling Program in C
*/
#include <stdio.h>
int main()
{
int pid[15];
int bt[15];
int n;
printf("Enter the number of processes: ");
scanf("%d",&n);
printf("Enter process id of all the processes: ");
for(int i=0;i<n;i++)
{
scanf("%d",&pid[i]);
}
printf("Enter burst time of all the processes: ");
for(int i=0;i<n;i++)
{
scanf("%d",&bt[i]);
}
int i, wt[n];
wt[0]=0;
//for calculating waiting time of each process
for(i=1; i<n; i++)
{
wt[i]= bt[i-1]+ wt[i-1];
}
printf("Process ID Burst Time Waiting Time TurnAround Time\n");
float twt=0.0;
float tat= 0.0;
for(i=0; i<n; i++)
{
printf("%d\t\t", pid[i]);
printf("%d\t\t", bt[i]);
printf("%d\t\t", wt[i]);
//calculating and printing turnaround time of each process
printf("%d\t\t", bt[i]+wt[i]);
printf("\n");
//for calculating total waiting time
twt += wt[i];
//for calculating total turnaround time
tat += (wt[i]+bt[i]);
}
float att,awt;
//for calculating average waiting time
awt = twt/n;
//for calculating average turnaround time
att = tat/n;
printf("Avg. waiting time= %f\n",awt);
printf("Avg. turnaround time= %f",att);
}
Program Explanation
1. Initialize two array pid[] and bt[] of size 15.
2. Ask the user for number of processes n.
3. Ask the user for process id and burst time for all n processes and store them into pid[] and bt[] respectively.
4. Calculate waiting time of each process by the formula wt[i] = wt[i-1] + bt[i-1].
5. Print Process Id, Burst Time, waiting time and Turnaround time of each process in tabular manner.
6. Calculate and print turnaround time of each process = bt[i] + wt[i].
7. Add waiting time of all the processes and store it in the variable twt.
8. Add turnaround time of all the processes and store it in the variable tat.
9. Calculate average waiting time as awt = twt/n.
10. Calculate average turnaround time as att = tat/n;
11. Print average waiting time and average turnaround time.
12. Exit.
Shortest Job First (SJF)
The shortest job first (SJF) or shortest job next, is a scheduling policy that selects the waiting process with the smallest execution time to execute next. SJN, also known as Shortest Job Next (SJN), can be preemptive or Non-Preemptive.
CODE:
/*
* C Program to Implement SJF Scheduling
*/
#include<stdio.h>
int main()
{
int bt[20],p[20],wt[20],tat[20],i,j,n,total=0,totalT=0,pos,temp;
float avg_wt,avg_tat;
printf("Enter number of process:");
scanf("%d",&n);
printf("\nEnter Burst Time:\n");
for(i=0;i<n;i++)
{
printf("p%d:",i+1);
scanf("%d",&bt[i]);
p[i]=i+1;
}
//sorting of burst times
for(i=0;i<n;i++)
{
pos=i;
for(j=i+1;j<n;j++)
{
if(bt[j]<bt[pos])
pos=j;
}
temp=bt[i];
bt[i]=bt[pos];
bt[pos]=temp;
temp=p[i];
p[i]=p[pos];
p[pos]=temp;
}
wt[0]=0;
//finding the waiting time of all the processes
for(i=1;i<n;i++)
{
wt[i]=0;
for(j=0;j<i;j++)
//individual WT by adding BT of all previous completed processes
wt[i]+=bt[j];
//total waiting time
total+=wt[i];
}
//average waiting time
avg_wt=(float)total/n;
printf("\nProcess\t Burst Time \tWaiting Time\tTurnaround Time");
for(i=0;i<n;i++)
{
//turnaround time of individual processes
tat[i]=bt[i]+wt[i];
//total turnaround time
totalT+=tat[i];
printf("\np%d\t\t %d\t\t %d\t\t\t%d",p[i],bt[i],wt[i],tat[i]);
}
//average turnaround time
avg_tat=(float)totalT/n;
printf("\n\nAverage Waiting Time=%f",avg_wt);
printf("\nAverage Turnaround Time=%f",avg_tat);
}
Program Explanation
1. Initialize two array pid[] and bt[] of size 20.
2. Ask the user for number of processes n.
3. Ask the user for process id and burst time for all n processes and store them into pid[] and bt[] respectively.
4. Sort all the processes according to their burst time.
5. Assign waiting time = 0 to the smallest process.
6. Calculate waiting time of each process by using two loops and adding all the burst time of previously completed processes.
7. Print Process Id, Burst Time, waiting time and Turnaround time of each process in tabular manner.
8. Calculate and print turnaround time of each process = bt[i] + wt[i].
9. Add waiting time of all the processes and store it in the variable total.
10. Add turnaround time of all the processes and store it in the variable totalT.
11. Calculate average waiting time as avg_wt = total/n.
12. Calculate average turnaround time as avg_tat = totalT/n;
13. Print average waiting time and average turnaround time.
14. Exit.
EXPERIMENT 3
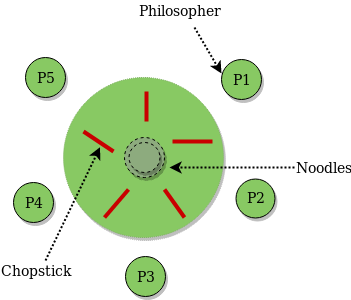
The Dining Philosopher Problem – The Dining Philosopher Problem states that K philosophers seated around a circular table with one chopstick between each pair of philosophers. There is one chopstick between each philosopher. A philosopher may eat if he can pick up the two chopsticks adjacent to him. One chopstick may be picked up by any one of its adjacent followers but not both.
Semaphore Solution to Dining Philosopher –
Each philosopher is represented by the following pseudocode:
process P[i]
while true do
{ THINK;
PICKUP(CHOPSTICK[i], CHOPSTICK[i+1 mod 5]);
EAT;
PUTDOWN(CHOPSTICK[i], CHOPSTICK[i+1 mod 5])
}There are three states of the philosopher: THINKING, HUNGRY, and EATING. Here there are two semaphores: Mutex and a semaphore array for the philosophers. Mutex is used such that no two philosophers may access the pickup or putdown at the same time. The array is used to control the behavior of each philosopher. But, semaphores can result in deadlock due to programming errors.
CODE:
#include <pthread.h>
#include <semaphore.h>
#include <stdio.h>
#define N 5
#define THINKING 2
#define HUNGRY 1
#define EATING 0
#define LEFT (phnum + 4) % N
#define RIGHT (phnum + 1) % N
int state[N];
int phil[N] = { 0, 1, 2, 3, 4 };
sem_t mutex;
sem_t S[N];
void test(int phnum)
{
if (state[phnum] == HUNGRY
&& state[LEFT] != EATING
&& state[RIGHT] != EATING) {
state[phnum] = EATING;
sleep(2);
printf("Philosopher %d takes fork %d and %d\n",
phnum + 1, LEFT + 1, phnum + 1);
printf("Philosopher %d is Eating\n", phnum + 1);
sem_post(&S[phnum]);
}
}
void take_fork(int phnum)
{
sem_wait(&mutex);
state[phnum] = HUNGRY;
printf("Philosopher %d is Hungry\n", phnum + 1);
test(phnum);
sem_post(&mutex);
sem_wait(&S[phnum]);
sleep(1);
}
void put_fork(int phnum)
{
sem_wait(&mutex);
state[phnum] = THINKING;
printf("Philosopher %d putting fork %d and %d down\n",
phnum + 1, LEFT + 1, phnum + 1);
printf("Philosopher %d is thinking\n", phnum + 1);
test(LEFT);
test(RIGHT);
sem_post(&mutex);
}
void* philosopher(void* num)
{
while (1) {
int* i = num;
sleep(1);
take_fork(*i);
sleep(0);
put_fork(*i);
}
}
int main()
{
int i;
pthread_t thread_id[N];
sem_init(&mutex, 0, 1);
for (i = 0; i < N; i++)
sem_init(&S[i], 0, 0);
for (i = 0; i < N; i++) {
pthread_create(&thread_id[i], NULL,
philosopher, &phil[i]);
printf("Philosopher %d is thinking\n", i + 1);
}
for (i = 0; i < N; i++)
pthread_join(thread_id[i], NULL);
}
EXPERIMENT 4
Why the Banker's Algorithm is called that?
The reason the banker's algorithm is so titled is because it is employed in the banking sector to determine whether or not to authorize a loan to an individual. Assume a bank has n account holders, each of whom has an individual balance of S. When someone requests for a loan, the bank first deducts the loan amount from the total amount of money it possesses, and only approves the loan if the balance is more than S. It is done because the bank can simply do it if every account holder shows up to get their money.
In other words, the bank would never arrange its funds in a way that would prevent it from meeting the demands of all of its clients. The bank would strive to maintain safety at all times.
CODE:
-
- #include <stdio.h>
- int main()
- {
-
-
- int n, m, i, j, k;
- n = 5;
- m = 3;
- int alloc[5][3] = {{0, 1, 0},
- {2, 0, 0},
- {3, 0, 2},
- {2, 1, 1},
- {0, 0, 2}};
-
- int max[5][3] = {{7, 5, 3},
- {3, 2, 2},
- {9, 0, 2},
- {2, 2, 2},
- {4, 3, 3}};
-
- int avail[3] = {3, 3, 2};
-
- int f[n], ans[n], ind = 0;
- for (k = 0; k < n; k++)
- {
- f[k] = 0;
- }
- int need[n][m];
- for (i = 0; i < n; i++)
- {
- for (j = 0; j < m; j++)
- need[i][j] = max[i][j] - alloc[i][j];
- }
- int y = 0;
- for (k = 0; k < 5; k++)
- {
- for (i = 0; i < n; i++)
- {
- if (f[i] == 0)
- {
- int flag = 0;
- for (j = 0; j < m; j++)
- {
- if (need[i][j] > avail[j])
- {
- flag = 1;
- break;
- }
- }
- if (flag == 0)
- {
- ans[ind++] = i;
- for (y = 0; y < m; y++)
- avail[y] += alloc[i][y];
- f[i] = 1;
- }
- }
- }
- }
- int flag = 1;
- for (int i = 0; i < n; i++)
- {
- if (f[i] == 0)
- {
- flag = 0;
- printf("The following system is not safe");
- break;
- }
- }
- if (flag == 1)
- {
- printf("Following is the SAFE Sequence\n");
- for (i = 0; i < n - 1; i++)
- printf(" P%d ->", ans[i]);
- printf(" P%d", ans[n - 1]);
- }
- return (0);
- }
EXPERIMENT 5
FIFO
The simplest algorithm for replacing pages is this one. The operating system maintains a queue for all of the memory pages in this method, with the oldest page at the front of the queue. The first page in the queue is chosen for removal when a page has to be replaced.
Implementation
Let the amount of pages that memory can store serve as the capacity. Set, the current collection of memory pages, shall be.
- 1. Begin turning the pages.
- i) If the set can hold no more pages.
- a) Add pages one at a time into the collection until it is full or all requests for pages have been fulfilled.
- b) Maintain the pages in the queue simultaneously to carry out FIFO.
- b) Increased page error
- ii) Other
- Do nothing if the current page is included in the collection.
- If not, either a) the current page in the string should be substituted for the first page in the queue since it was the first to be placed into memory, or b) the first page in the queue should be removed.
- b) Add the currently viewing page to the queue.
- d) Page faults that increase.
- 2. Return page errors.
code :
- #include < stdio.h >
- int main()
- {
- int incomingStream[] = {4 , 1 , 2 , 4 , 5};
- int pageFaults = 0;
- int frames = 3;
- int m, n, s, pages;
- pages = sizeof(incomingStream)/sizeof(incomingStream[0]);
- printf(" Incoming \ t Frame 1 \ t Frame 2 \ t Frame 3 ");
- int temp[ frames ];
- for(m = 0; m < frames; m++)
- {
- temp[m] = -1;
- }
- for(m = 0; m < pages; m++)
- {
- s = 0;
- for(n = 0; n < frames; n++)
- {
- if(incomingStream[m] == temp[n])
- {
- s++;
- pageFaults--;
- }
- }
- pageFaults++;
- if((pageFaults <= frames) && (s == 0))
- {
- temp[m] = incomingStream[m];
- }
- else if(s == 0)
- {
- temp[(pageFaults - 1) % frames] = incomingStream[m];
- }
- printf("\n");
- printf("%d\t\t\t",incomingStream[m]);
- for(n = 0; n < frames; n++)
- {
- if(temp[n] != -1)
- printf(" %d\t\t\t", temp[n]);
- else
- printf(" - \t\t\t");
- }
- }
- printf("\nTotal Page Faults:\t%d\n", pageFaults);
- return 0;
- }
In Least Recently Used (LRU) algorithm is a Greedy algorithm where the page to be replaced is least recently used. The idea is based on locality of reference, the least recently used page is not likely
Let say the page reference string 7 0 1 2 0 3 0 4 2 3 0 3 2 . Initially we have 4 page slots empty.
Initially all slots are empty, so when 7 0 1 2 are allocated to the empty slots —> 4 Page faults
0 is already there so —> 0 Page fault.
when 3 came it will take the place of 7 because it is least recently used —>1 Page fault
0 is already in memory so —> 0 Page fault.
4 will takes place of 1 —> 1 Page Fault
Now for the further page reference string —> 0 Page fault because they are already available in the memory.
#include<bits/stdc++.h>
using namespace std;
int pageFaults(int pages[], int n, int capacity)
{
unordered_set<int> s;
unordered_map<int, int> indexes;
int page_faults = 0;
for (int i=0; i<n; i++)
{
if (s.size() < capacity)
{
if (s.find(pages[i])==s.end())
{
s.insert(pages[i]);
page_faults++;
}
indexes[pages[i]] = i;
}
else
{
if (s.find(pages[i]) == s.end())
{
int lru = INT_MAX, val;
for (auto it=s.begin(); it!=s.end(); it++)
{
if (indexes[*it] < lru)
{
lru = indexes[*it];
val = *it;
}
}
s.erase(val);
s.insert(pages[i]);
page_faults++;
}
indexes[pages[i]] = i;
}
}
return page_faults;
}
int main()
{
int pages[] = {7, 0, 1, 2, 0, 3, 0, 4, 2, 3, 0, 3, 2};
int n = sizeof(pages)/sizeof(pages[0]);
int capacity = 4;
cout << pageFaults(pages, n, capacity);
return 0;
}
EXPERIMENT 6
FIRST FIT:
#include <stdio.h>
void implimentFirstFit(int blockSize[], int blocks, int processSize[], int processes)
{
// This will store the block id of the allocated block to a process
int allocate[processes];
int occupied[blocks];
// initially assigning -1 to all allocation indexes
// means nothing is allocated currently
for(int i = 0; i < processes; i++)
{
allocate[i] = -1;
}
for(int i = 0; i < blocks; i++){
occupied[i] = 0;
}
// take each process one by one and find
// first block that can accomodate it
for (int i = 0; i < processes; i++)
{
for (int j = 0; j < blocks; j++)
{
if (!occupied[j] && blockSize[j] >= processSize[i])
{
// allocate block j to p[i] process
allocate[i] = j;
occupied[j] = 1;
break;
}
}
}
printf("\nProcess No.\tProcess Size\tBlock no.\n");
for (int i = 0; i < processes; i++)
{
printf("%d \t\t\t %d \t\t\t", i+1, processSize[i]);
if (allocate[i] != -1)
printf("%d\n",allocate[i] + 1);
else
printf("Not Allocated\n");
}
}
void main()
{
int blockSize[] = {30, 5, 10};
int processSize[] = {10, 6, 9};
int m = sizeof(blockSize)/sizeof(blockSize[0]);
int n = sizeof(processSize)/sizeof(processSize[0]);
implimentFirstFit(blockSize, m, processSize, n);
}
Best Fit:
#include <stdio.h>
void implimentBestFit(int blockSize[], int blocks, int processSize[], int proccesses)
{
// This will store the block id of the allocated block to a process
int allocation[proccesses];
int occupied[blocks];
// initially assigning -1 to all allocation indexes
// means nothing is allocated currently
for(int i = 0; i < proccesses; i++){
allocation[i] = -1;
}
for(int i = 0; i < blocks; i++){
occupied[i] = 0;
}
// pick each process and find suitable blocks
// according to its size ad assign to it
for (int i = 0; i < proccesses; i++)
{
int indexPlaced = -1;
for (int j = 0; j < blocks; j++) {
if (blockSize[j] >= processSize[i] && !occupied[j])
{
// place it at the first block fit to accomodate process
if (indexPlaced == -1)
indexPlaced = j;
// if any future block is smalller than the current block where
// process is placed, change the block and thus indexPlaced
// this reduces the wastage thus best fit
else if (blockSize[j] < blockSize[indexPlaced])
indexPlaced = j;
}
}
// If we were successfully able to find block for the process
if (indexPlaced != -1)
{
// allocate this block j to process p[i]
allocation[i] = indexPlaced;
// make the status of the block as occupied
occupied[indexPlaced] = 1;
}
}
printf("\nProcess No.\tProcess Size\tBlock no.\n");
for (int i = 0; i < proccesses; i++)
{
printf("%d \t\t\t %d \t\t\t", i+1, processSize[i]);
if (allocation[i] != -1)
printf("%d\n",allocation[i] + 1);
else
printf("Not Allocated\n");
}
}
// Driver code
int main()
{
int blockSize[] = {100, 50, 30, 120, 35};
int processSize[] = {40, 10, 30, 60};
int blocks = sizeof(blockSize)/sizeof(blockSize[0]);
int proccesses = sizeof(processSize)/sizeof(processSize[0]);
implimentBestFit(blockSize, blocks, processSize, proccesses);
return 0 ;
}
worst fit:
#include <stdio.h>
void implimentWorstFit(int blockSize[], int blocks, int processSize[], int processes)
{
// This will store the block id of the allocated block to a process
int allocation[processes];
int occupied[blocks];
// initially assigning -1 to all allocation indexes
// means nothing is allocated currently
for(int i = 0; i < processes; i++){
allocation[i] = -1;
}
for(int i = 0; i < blocks; i++){
occupied[i] = 0;
}
// pick each process and find suitable blocks
// according to its size ad assign to it
for (int i=0; i < processes; i++)
{
int indexPlaced = -1;
for(int j = 0; j < blocks; j++)
{
// if not occupied and block size is large enough
if(blockSize[j] >= processSize[i] && !occupied[j])
{
// place it at the first block fit to accomodate process
if (indexPlaced == -1)
indexPlaced = j;
// if any future block is larger than the current block where
// process is placed, change the block and thus indexPlaced
else if (blockSize[indexPlaced] < blockSize[j])
indexPlaced = j;
}
}
// If we were successfully able to find block for the process
if (indexPlaced != -1)
{
// allocate this block j to process p[i]
allocation[i] = indexPlaced;
// make the status of the block as occupied
occupied[indexPlaced] = 1;
// Reduce available memory for the block
blockSize[indexPlaced] -= processSize[i];
}
}
printf("\nProcess No.\tProcess Size\tBlock no.\n");
for (int i = 0; i < processes; i++)
{
printf("%d \t\t\t %d \t\t\t", i+1, processSize[i]);
if (allocation[i] != -1)
printf("%d\n",allocation[i] + 1);
else
printf("Not Allocated\n");
}
}
// Driver code
int main()
{
int blockSize[] = {100, 50, 30, 120, 35};
int processSize[] = {40, 10, 30, 60};
int blocks = sizeof(blockSize)/sizeof(blockSize[0]);
int processes = sizeof(processSize)/sizeof(processSize[0]);
implimentWorstFit(blockSize, blocks, processSize, processes);
return 0;
}
\
FCFS is the simplest disk scheduling algorithm. As the name suggests, this algorithm entertains requests in the order they arrive in the disk queue. The algorithm looks very fair and there is no starvation (all requests are serviced sequentially) but generally, it does not provide the fastest service.
Algorithm:
Let Request array represents an array storing indexes of tracks that have been requested in ascending order of their time of arrival. ‘head’ is the position of disk head.
Let us one by one take the tracks in default order and calculate the absolute distance of the track from the head.
Increment the total seek count with this distance.
Currently serviced track position now becomes the new head position.
Go to step 2 until all tracks in request array have not been serviced.
code:
#include <stdio.h>
#include <math.h>
int size = 8;
void FCFS(int arr[],int head)
{
int seek_count = 0;
int cur_track, distance;
for(int i=0;i<size;i++)
{
cur_track = arr[i];
distance = fabs(head - cur_track);
seek_count += distance;
head = cur_track;
}
printf("Total number of seek operations: %d\n",seek_count);
printf("Seek Sequence is\n");
for (int i = 0; i < size; i++) {
printf("%d\n",arr[i]);
}
}
int main()
{
int arr[8] = { 176, 79, 34, 60, 92, 11, 41, 114 };
int head = 50;
FCFS(arr,head);
return 0;
}
Shortest Seek Time First (SSTF) –
Basic idea is the tracks which are closer to current disk head position should be serviced first in order to minimise the seek operations.
Advantages of Shortest Seek Time First (SSTF) –
Better performance than FCFS scheduling algorithm.
It provides better throughput.
This algorithm is used in Batch Processing system where throughput is more important.
It has less average response and waiting time.
Disadvantages of Shortest Seek Time First (SSTF) –
Starvation is possible for some requests as it favours easy to reach request and ignores the far away processes.
There is lack of predictability because of high variance of response time.
Switching direction slows things down.
Algorithm –
Let Request array represents an array storing indexes of tracks that have been requested. ‘head’ is the position of disk head.
Find the positive distance of all tracks in the request array from head.
Find a track from requested array which has not been accessed/serviced yet and has minimum distance from head.
Increment the total seek count with this distance.
Currently serviced track position now becomes the new head position.
Go to step 2 until all tracks in request array have not been serviced.
CODE:
#include <bits/stdc++.h>
using namespace std;
void calculatedifference(int request[], int head,
int diff[][2], int n)
{
for(int i = 0; i < n; i++)
{
diff[i][0] = abs(head - request[i]);
}
}
int findMIN(int diff[][2], int n)
{
int index = -1;
int minimum = 1e9;
for(int i = 0; i < n; i++)
{
if (!diff[i][1] && minimum > diff[i][0])
{
minimum = diff[i][0];
index = i;
}
}
return index;
}
void shortestSeekTimeFirst(int request[],
int head, int n)
{
if (n == 0)
{
return;
}
int diff[n][2] = { { 0, 0 } };
int seekcount = 0;
int seeksequence[n + 1] = {0};
for(int i = 0; i < n; i++)
{
seeksequence[i] = head;
calculatedifference(request, head, diff, n);
int index = findMIN(diff, n);
diff[index][1] = 1;
seekcount += diff[index][0];
head = request[index];
}
seeksequence[n] = head;
cout << "Total number of seek operations = "
<< seekcount << endl;
cout << "Seek sequence is : " << "\n";
for(int i = 0; i <= n; i++)
{
cout << seeksequence[i] << "\n";
}
}
int main()
{
int n = 8;
int proc[n] = { 176, 79, 34, 60, 92, 11, 41, 114 };
shortestSeekTimeFirst(proc, 50, n);
return 0;
}